New for Amazon SageMaker – Perform Shadow Tests to Compare Inference Performance Between ML Model Variants
As you move your machine learning (ML) workloads into production, you need to continuously monitor your deployed models and iterate when you observe a deviation in your model performance. When you build a new model, you typically start validating the model offline using historical inference request data. But this data sometimes fails to account for current, real-world conditions. For example, new products might become trending that your product recommendation model hasn’t seen yet. Or, you experience a sudden spike in the volume of inference requests in production that you never exposed your model to before.
Today, I’m excited to announce Amazon SageMaker support for shadow testing!
Deploying a model in shadow mode lets you conduct a more holistic test by routing a copy of the live inference requests for a production model to the new (shadow) model. Yet, only the responses from the production model are returned to the calling application. Shadow testing helps you build further confidence in your model and catch potential configuration errors and performance issues before they impact end users. Once you complete a shadow test, you can use the deployment guardrails for SageMaker inference endpoints to safely update your model in production.
Get Started with Amazon SageMaker Shadow Testing
You can create shadow tests using the new SageMaker Inference Console and APIs. Shadow testing gives you a fully managed experience for setup, monitoring, viewing, and acting on the results of shadow tests. If you have existing workflows built around SageMaker endpoints, you can also deploy a model in shadow mode using the existing SageMaker Inference APIs.
On the SageMaker console, select Inference and Shadow tests to create, monitor, and deploy shadow tests.
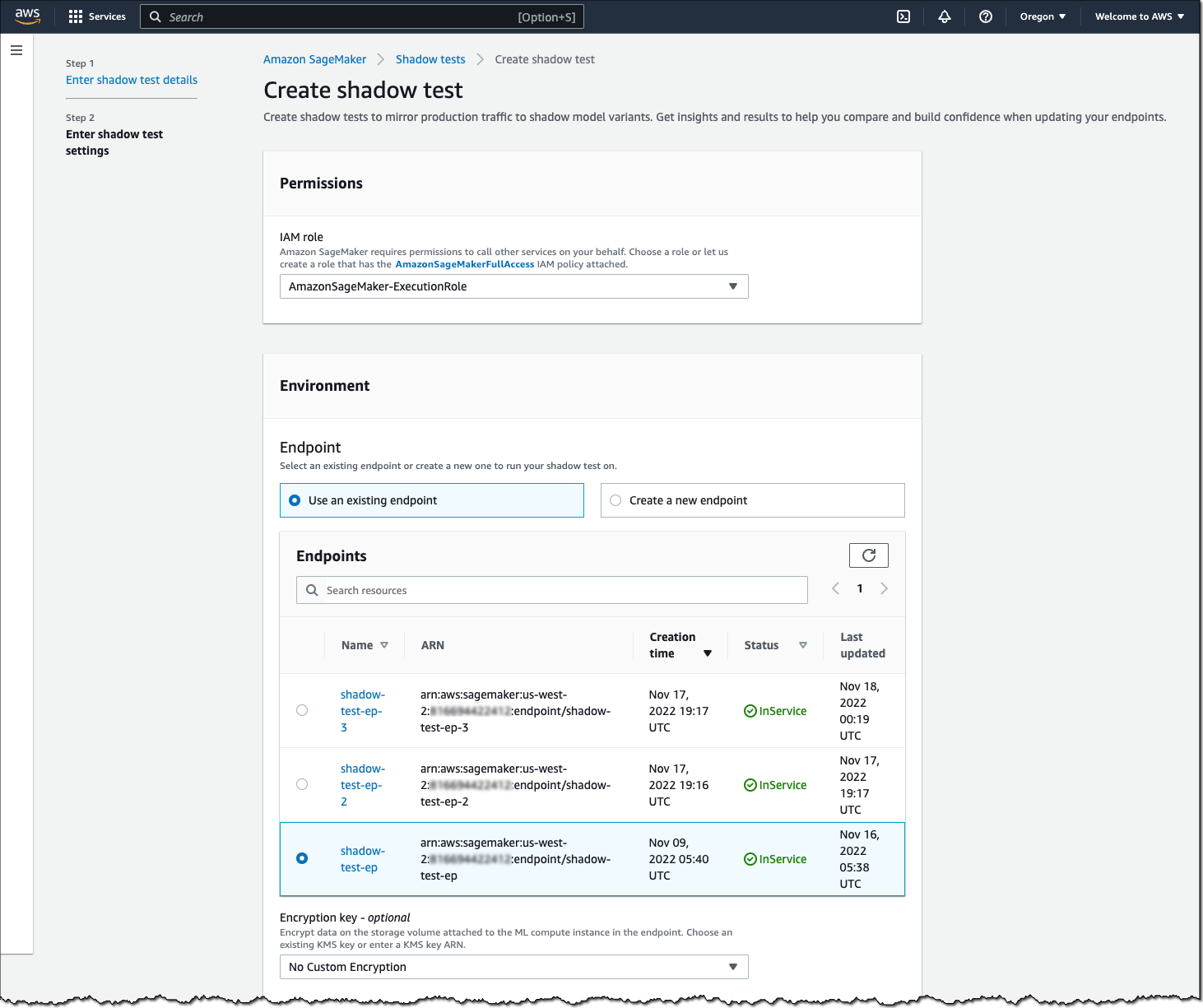
To create a shadow test, select an existing (or create a new) SageMaker endpoint and production variant you want to test against.
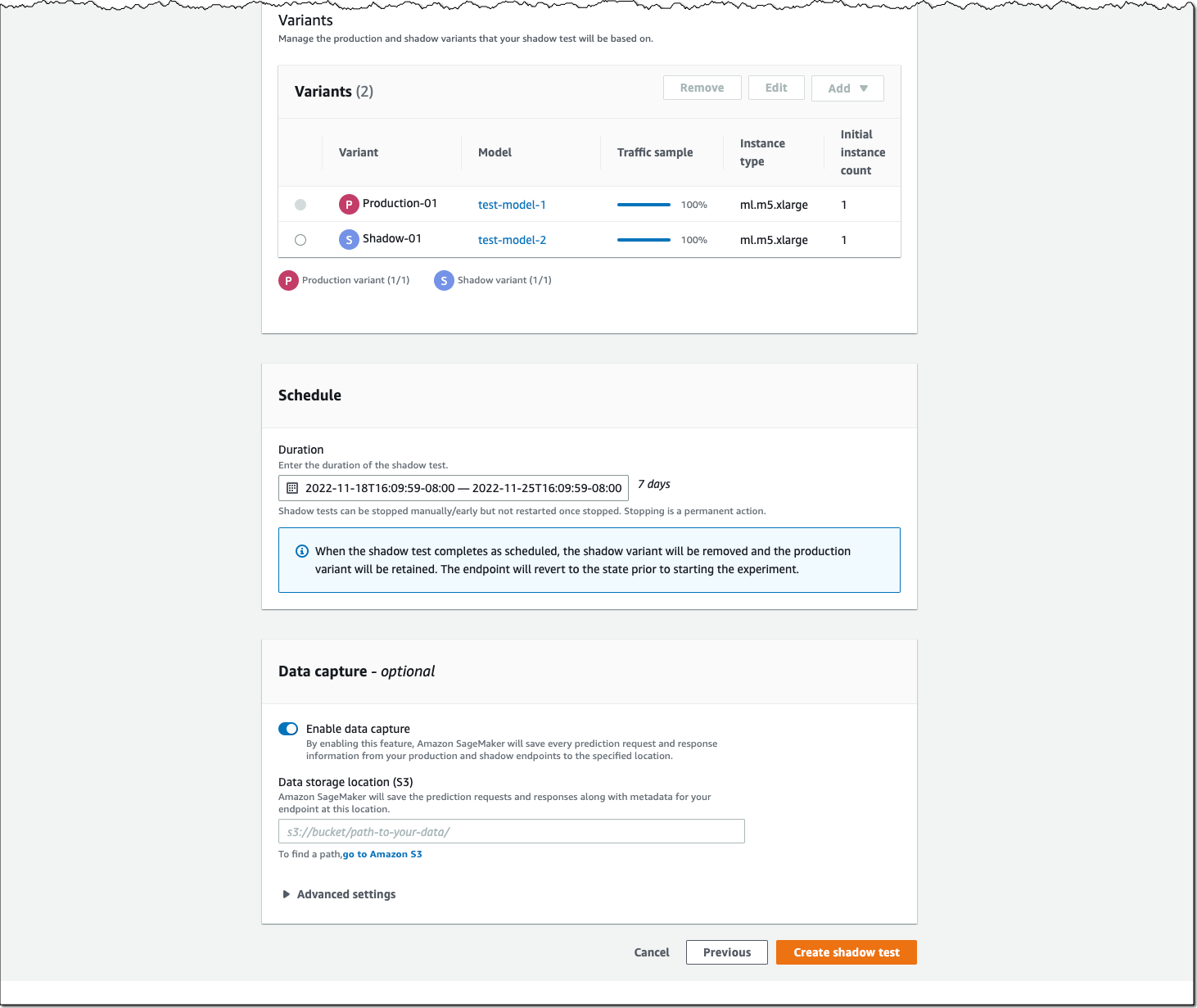
Next, configure the proportion of traffic to send to the shadow variant, the comparison metrics you want to evaluate, and the duration of the test. You can also enable data capture for your production and shadow variant.
That’s it. SageMaker now automatically deploys the new variant in shadow mode and routes a copy of the inference requests to it in real time, all within the same endpoint. The following diagram illustrates this workflow.
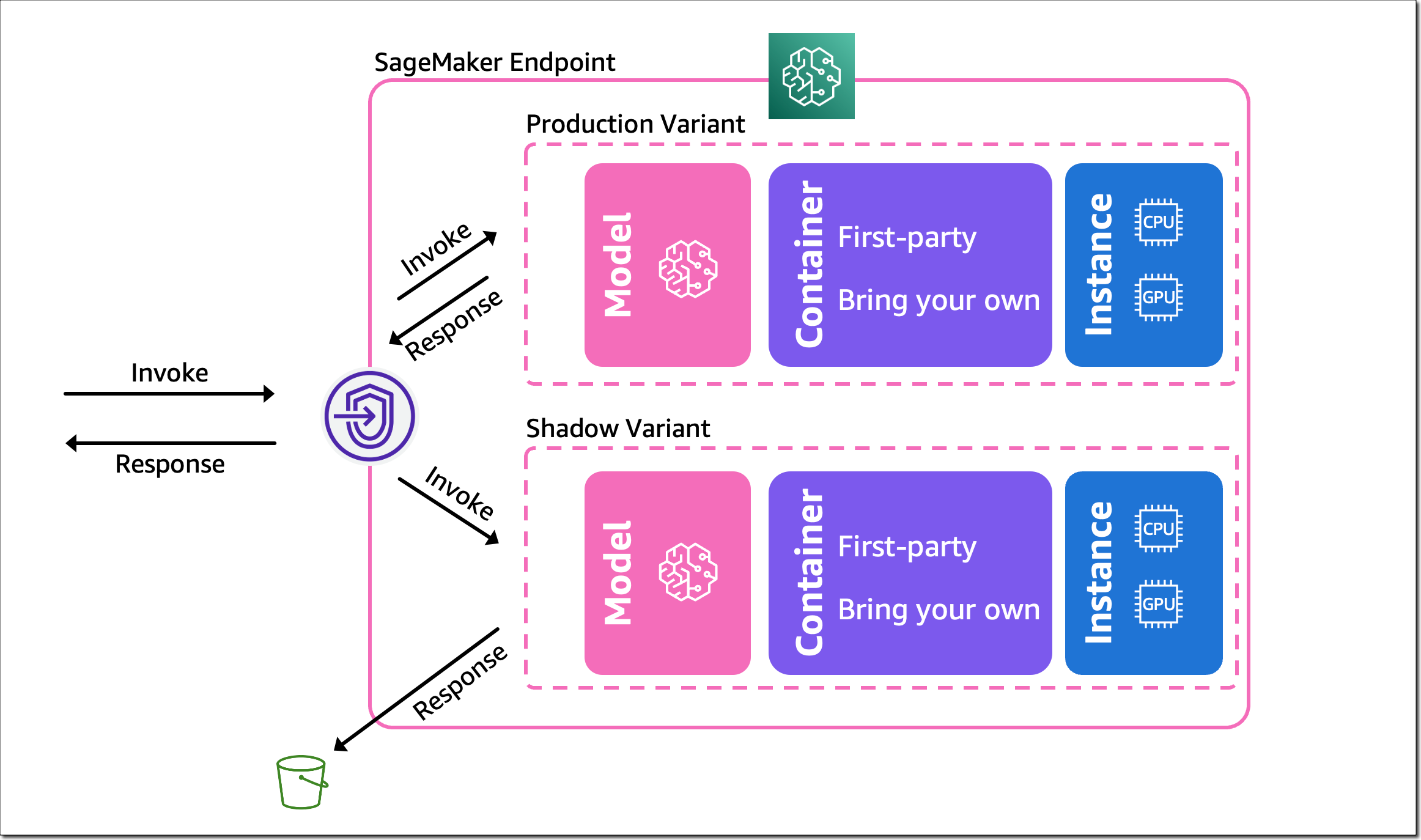
Note that only the responses of the production variant are returned to the calling application. You can choose to either discard or log the responses of the shadow variant for offline comparison.
You can also use shadow testing to validate changes you made to any component in your production variant, including the serving container or ML instance. This can be useful when you’re upgrading to a new framework version of your serving container, applying patches, or if you want to make sure that there is no impact to latency or error rate due to this change. Similarly, if you consider moving to another ML instance type, for example, Amazon EC2 C7g instances based on AWS Graviton processors, or EC2 G5 instances powered by NVIDIA A10G Tensor Core GPUs, you can use shadow testing to evaluate the performance on production traffic prior to rollout.
You can monitor the progress of the shadow test and performance metrics such as latency and error rate through a live dashboard. On the SageMaker console, select Inference and Shadow tests, then select the shadow test you want to monitor.
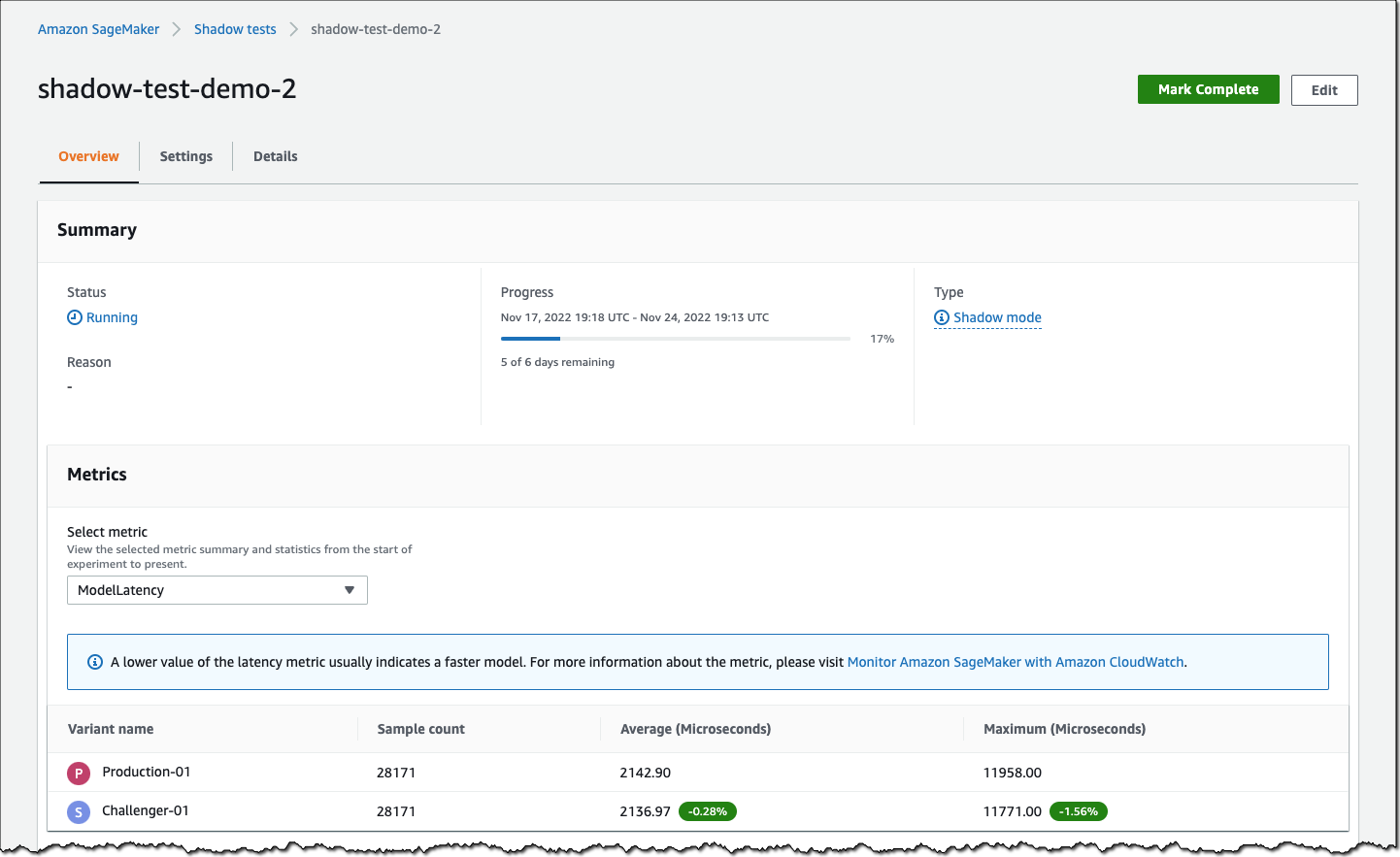
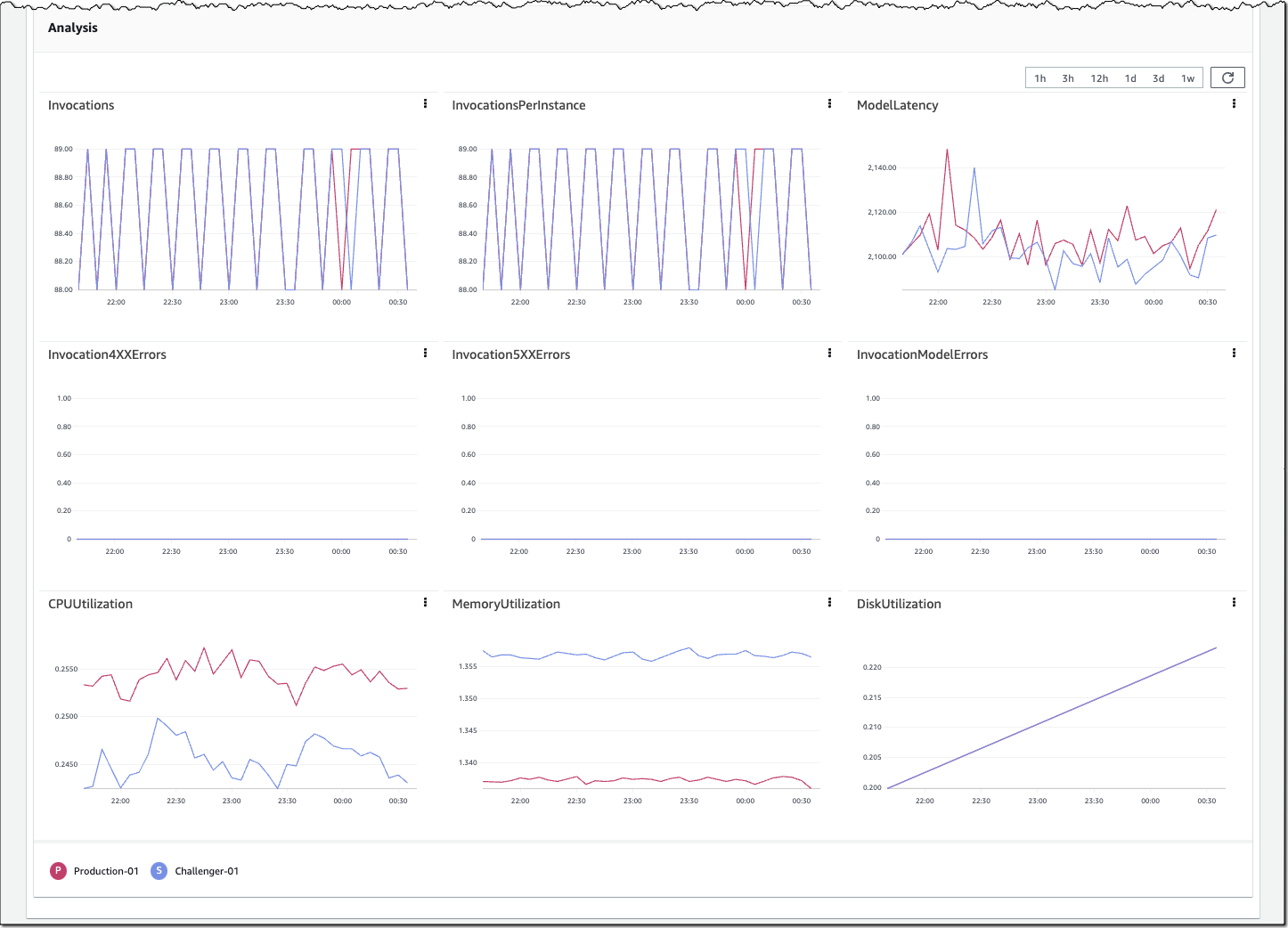
If you decide to promote the shadow model to production, select Deploy shadow variant and define the infrastructure configuration to deploy the shadow variant.
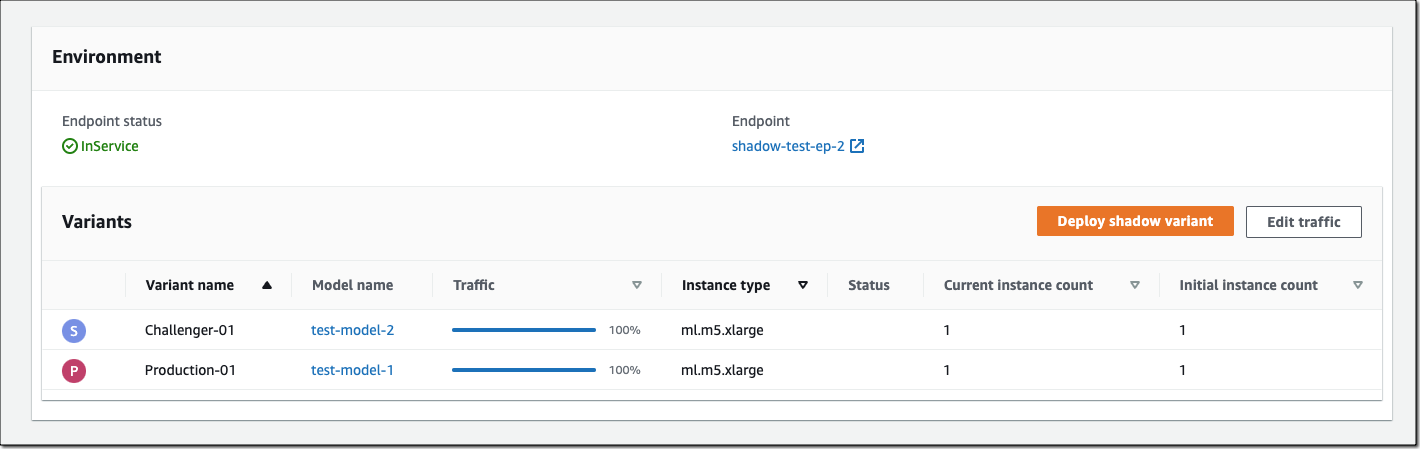
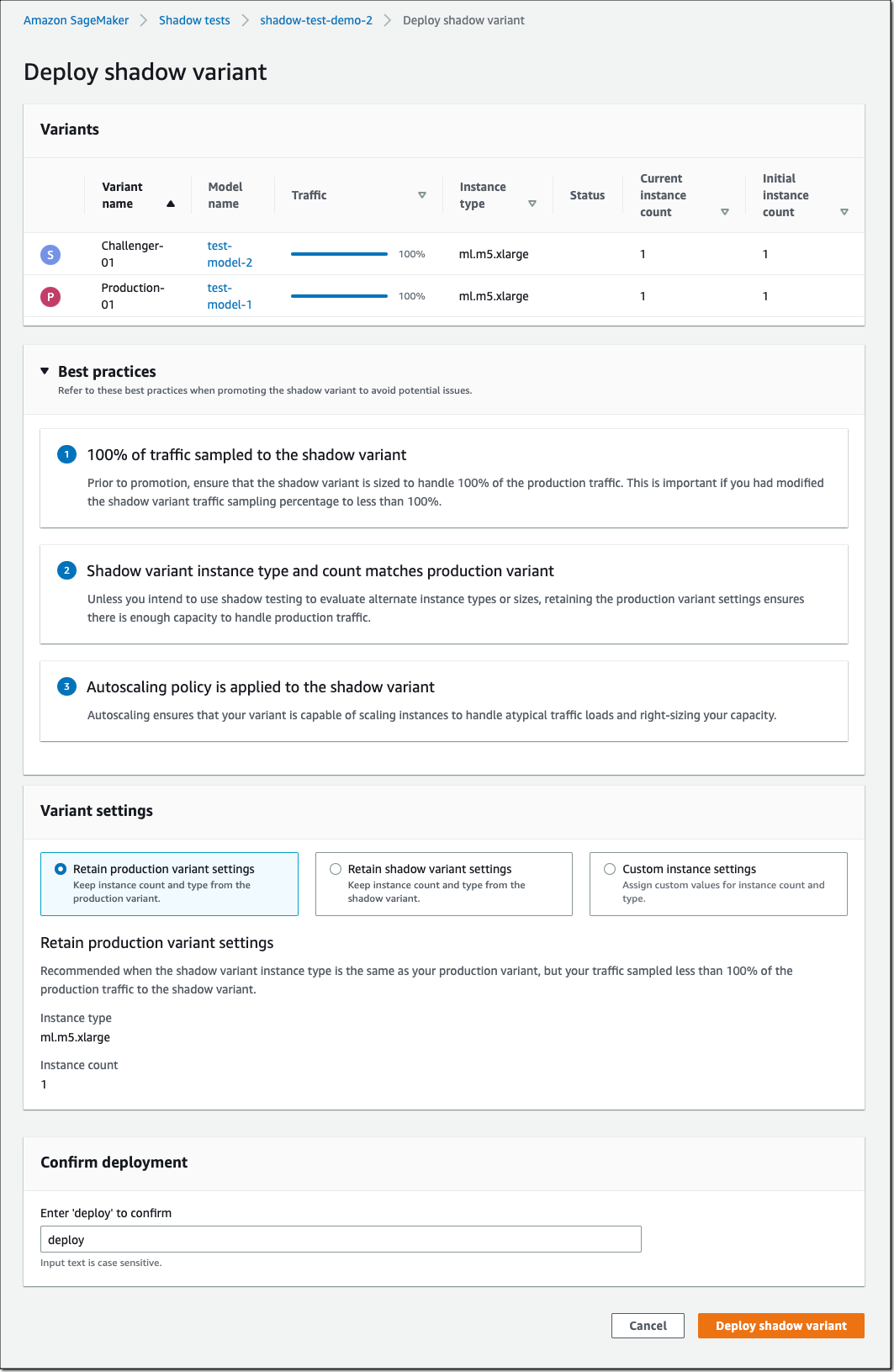
You can also use the SageMaker deployment guardrails if you want to add linear or canary traffic shifting modes and auto rollbacks to your update.
Availability and Pricing
SageMaker support for shadow testing is available today in all AWS Regions where SageMaker hosting is available except for the AWS GovCloud (US) Regions and AWS China Regions.
There is no additional charge for SageMaker shadow testing other than usage charges for the ML instances and ML storage provisioned to host the shadow variant. The pricing for ML instances and ML storage dimensions is the same as the real-time inference option. There is no additional charge for data processed in and out of shadow deployments. The SageMaker pricing page has all the details.
To learn more, visit Amazon SageMaker shadow testing.
Start validating your new ML models with SageMaker shadow tests today!
— Antje