Introducing Athena Provisioned Capacity
Today we launch the ability to provision capacity to run your Athena queries.
Athena is a query service that makes it simple to analyze data in Amazon Simple Storage Service (Amazon S3) data lakes and 30 different data sources, including on-premises data sources or other cloud systems, using standard SQL queries. Athena is serverless, so there is no infrastructure to manage, and–until today–you pay only for the queries that you run. Starting today, you can get dedicated capacity for your queries and use new workload management features to prioritize, control, and scale your most important queries, paying only for the capacity you provision.
At AWS, 90 percent of the new services and features are driven by your direct feedback. Many of you Athena customers told us that, when running a large volume of queries, you sometimes experience queuing, which might slow down some applications or business processes. To work around this, you typically create a query prioritization mechanism to prioritize mission-critical queries over less critical, interactive, or exploratory queries. This prioritization mechanism helps to get the highest priority queries run first, at the price of building and maintaining code or business processes outside of Athena itself. You also told us it is difficult to forecast your Athena costs. Athena charges by the volume of data scanned, which is often difficult to predict as it depends on the size of your data set, the construction of the user queries, and the storage format for the data.
We heard this feedback, and today, we introduce the capability to provision dedicated query processing capacity at scale. With provisioned capacity, you provision a dedicated set of compute resources to run your queries. This always-on capacity can serve your business-critical queries with near-zero latency and no queuing. It gives you control over workload performance characteristics such as cost, concurrency, and query prioritization. Similar to provisioned capacity for other AWS services, you pay only for the capacity provisioned, not for the actual usage. With provisioned capacity, your Athena bills are predictable, and you do not have to limit user queries to stay within your monthly budget. I’ll share more about the billing model down below.
Behind the scenes, Athena maintains a large pool of compute in each AWS Region that it operates in. You can think of this as one large pool of compute, divided logically across customers. When you reserve capacity in Athena, the capacity is held for your exclusive use. You can choose which queries run on the capacity you provisioned and which run on Athena’s multi-tenant, on-demand capacity. Multiple queries can share the capacity you provisioned. You may add additional capacity units at any time, based on your evolving business requirements. You may also adjust the provisioned capacity down after a minimum period of time of 8 hours.
The unit of capacity is a Data Processing Unit (DPU). A single DPU is equivalent to four vCPU and 16 Gb RAM. The minimum capacity you may provision is 24 DPU for 8 hours. This new provisioned capacity for Athena is ideal for those of you running any volume of queries, but the sweet spot to start using provisioned capacity is when you spend $100 or more per month on Athena.
The number of DPUs you need depends on your goals and analysis patterns. For example, if you need queries to start immediately and without queuing, you should provision enough DPUs to meet your peak concurrent query demand. Provisioning fewer DPUs than your peak demand is allowed, but may result in queuing. When this occurs, queries are held in a queue and executed when capacity is available. If your goal is to run queries within a fixed budget, you can use the AWS Pricing Calculator to determine the number of DPUs that meets your budget. Lastly, remember that data size, storage format, and query construction influence the number of DPU a query requires. You can increase query performance by compressing, partitioning, and converting your data into columnar formats. Athena’s documentation provides you with guidelines to determine how much capacity you might require to run multiple queries at the same time.
How Does It Work?
Getting started is a three-step process. I navigate to the Athena page in the AWS Management Console and select Capacity Reservations on the left-side navigation menu.

I select the Create capacity reservation button at the top right of the page.
On the Create capacity reservation page, I enter a Capacity reservation name and the number of DPUs I want to provision.

I select Review to review my choices, and I select Create capacity reservation to create my reservation. After a brief period of time, the capacity reservation status becomes  Active.
Active.

The third and last step is to create a workgroup and assign the workgroup to the provisioned capacity. A workgroup is an Athena mechanism allowing you to separate users, teams, applications, or workloads to set limits on the amount of data each query or the entire workgroup can process and to track costs.
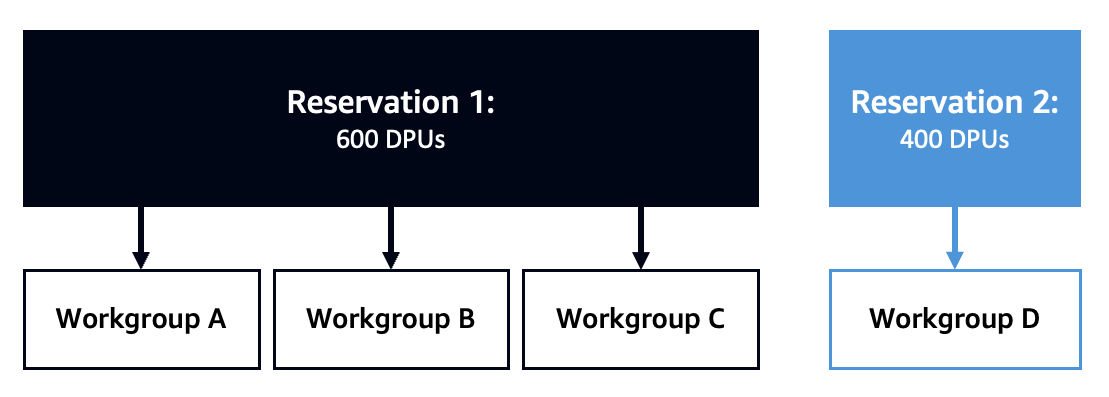
Queries belonging to the assigned workgroup will run on the capacity you provisioned. Capacity may be shared with multiple workgroups as long as they all use the same Athena engine version. This concept, depicted in the diagram below, is surfaced through a capacity allocation policy, which defines how capacity is assigned over workgroups. This gives you the flexibility to run queries with more or less capacity, depending on your business needs.
To create a workgroup, I navigate to the Workgroups section of the Athena page. Then, I select Create workgroup.

I make sure the analytics engine selected in the reservation matches the one in the workgroup.
 Then, I go back to the capacity reservation I just created, and I select Add workgroups to add the workgroup I just created.
Then, I go back to the capacity reservation I just created, and I select Add workgroups to add the workgroup I just created.

That’s it! Now that the configuration is ready, I can run my queries. Existing queries will run on the provisioned capacity unmodified. I make sure to select the workgroup I just created when I run queries. I choose a workgroup on the top right side of the query editor, or use the --work-group argument on the AWS command line, such as:
aws athena start-query-execution --work-group AWSNewsBlog
Availability and Pricing
As I explained in the introduction, we charge for the number of DPUs you provisioned and the duration. The minimum duration is 8 hours, and after that, billing is per minute. You can release the provisioned capacity at any time. Cancellations within the minimum duration period are billed for the full term, and capacity is deallocated as soon as all currently running queries are terminated.
Queries run from a workgroup assigned to a provisioned capacity are not billed for the amount of data scanned. You effectively pay a flat rate depending on the provisioned capacity, not the usage. If you have excess capacity, you can reduce the number of DPUs you provisioned or add workgroups to consume the excess capacity.
As usual, the Athena pricing page has all the details.
Athena provisioned capacity is available today in US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), and Europe (Ireland, Stockholm) AWS Regions.