Automated in-AWS Failback for AWS Elastic Disaster Recovery
I first covered AWS Elastic Disaster Recovery (DRS) in a 2021 blog post. In that post, I described how DRS “enables customers to use AWS as an elastic recovery site for their on-premises applications without needing to invest in on-premises DR infrastructure that lies idle until needed. Once enabled, DRS maintains a constant replication posture for your operating systems, applications, and databases.” I’m happy to announce that, today, DRS now also supports in-AWS failback, adding to the existing support for non-disruptive recovery drills and on-premises failback included in the original release.
I also wrote in my earlier post that drills are an important part of disaster recovery since, if you don’t test, you simply won’t know for sure that your disaster recovery solution will work properly when you need it to. However, customers rarely like to test because it’s a time-consuming activity and also disruptive. Automation and simplification encourage frequent drills, even at scale, enabling you to be better prepared for disaster, and now you can use them irrespective of whether your applications are on-premises or in AWS. Non-disruptive recovery drills provide confidence that you will meet your recovery time objectives (RTOs) and recovery point objectives (RPOs) should you ever need to initiate a recovery or failback. More information on RTOs and RPOs, and why they’re important to define, can be found in the recovery objectives documentation.
The new automated support provides a simplified and expedited experience to fail back Amazon Elastic Compute Cloud (Amazon EC2) instances to the original Region, and both failover and failback processes (for on-premises or in-AWS recovery) can be conveniently started from the AWS Management Console. Also, for customers that want to customize the granular steps that make up a recovery workflow, DRS provides three new APIs, linked at the bottom of this post.
Failover vs. Failback
Failover is switching the running application to another Availability Zone, or even a different Region, should outages or issues occur that threaten the availability of the application. Failback is the process of returning the application to the original on-premises location or Region. For failovers to another Availability Zone, customers who are agnostic to the zone may continue running the application in its new zone indefinitely if so required. In this case, they will reverse the recovery replication, so the recovered instance is protected for future recovery. However, if the failover was to a different Region, its likely customers will want to eventually fail back and return to the original Region when the issues that caused failover have been resolved.
The below images illustrate architectures for in-AWS applications protected by DRS. The architecture in the image below is for cross-Availability Zone scenarios.
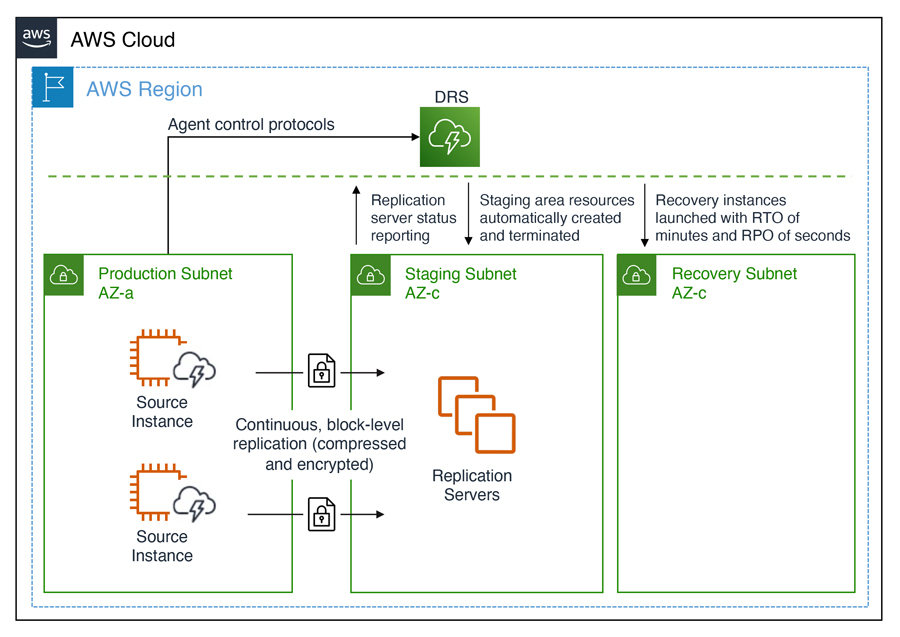
The architecture diagram below is for cross-Region scenarios.

Let’s assume an incident occurs with an in-AWS application, so we initiate a failover to another AWS Region. When the issue has been resolved, we want to fail back to the original Region. The following animation illustrates the failover and failback processes.
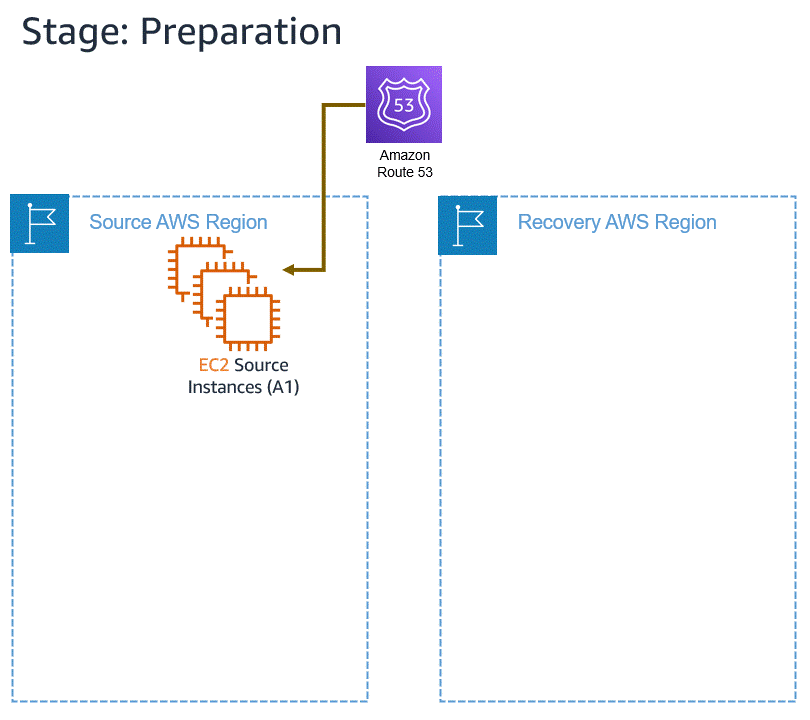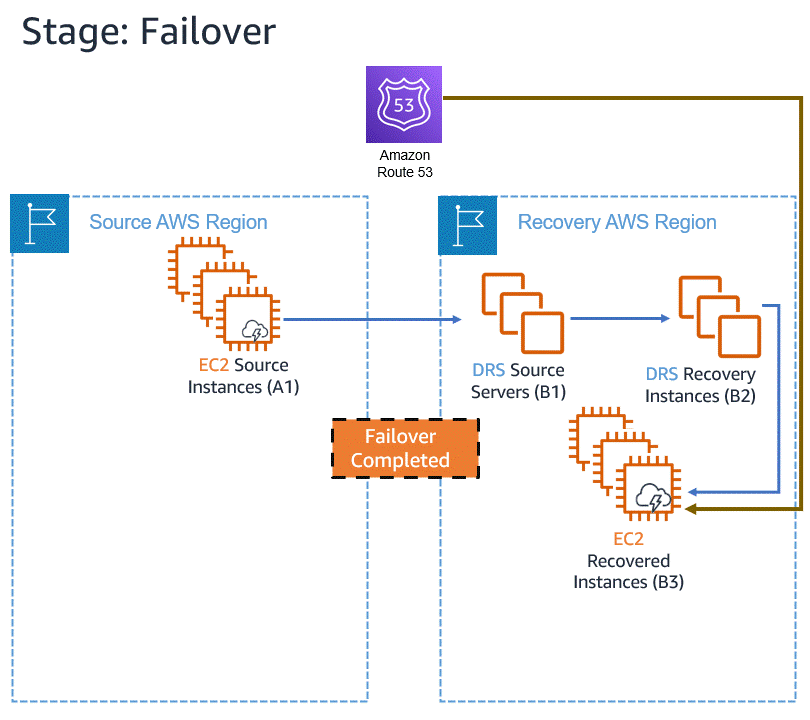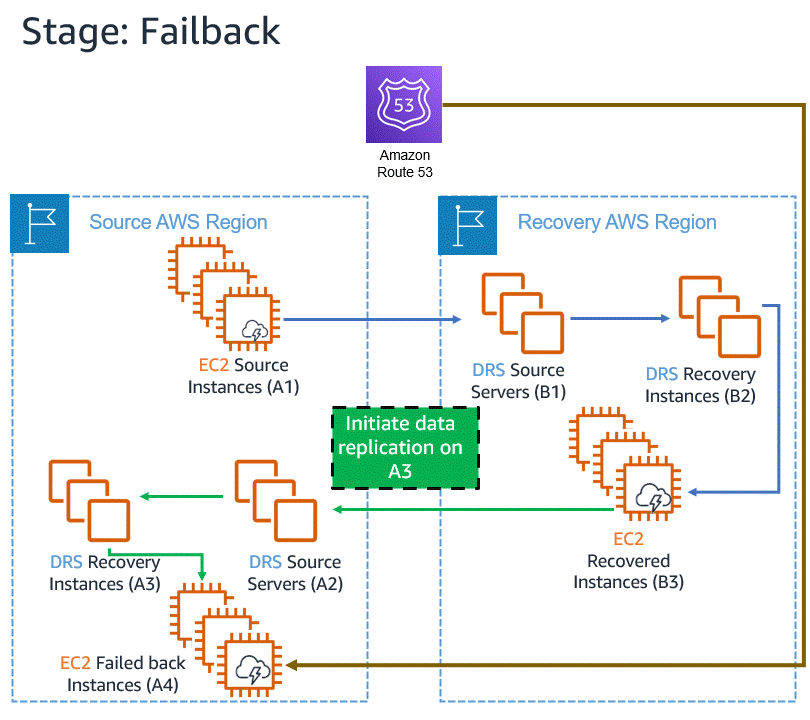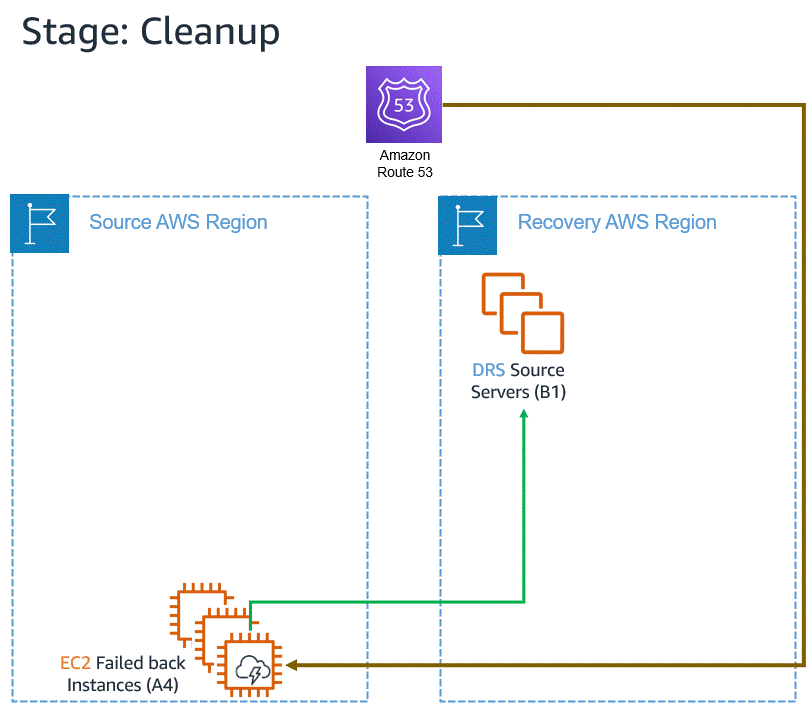
Learn more about in-AWS failback with Elastic Disaster Recovery
As I mentioned earlier, three new APIs are also available for customers who want to customize the granular steps involved. The documentation for these can be found using the links below.
The new in-AWS failback support is available in all Regions where AWS Elastic Disaster Recovery is available. Learn more about AWS Elastic Disaster Recovery in the User Guide. For specific information on the new failback support I recommend consulting this topic in the service User Guide.
— Steve