Join the preview of Amazon Aurora Limitless Database
Today, we are announcing the preview of Amazon Aurora Limitless Database, a new capability supporting automated horizontal scaling to process millions of write transactions per second and manage petabytes of data in a single Aurora database.
Amazon Aurora read replicas allow you to increase the read capacity of your Aurora cluster beyond the limits of what a single database instance can provide. Now, Aurora Limitless Database scales write throughput and storage capacity of your database beyond the limits of a single Aurora writer instance. The compute and storage capacity that is used for Limitless Database is in addition to and independent of the capacity of your writer and reader instances in the cluster.
With Limitless Database, you can focus on building high-scale applications without having to build and maintain complex solutions for scaling your data across multiple database instances to support your workloads. Aurora Limitless Database scales based on the workload to support write throughput and storage capacity that, until today, would require multiple Aurora writer instances.
The architecture of Amazon Aurora Limitless Database
Limitless Database has a two-layer architecture consisting of multiple database nodes, either transaction routers or shards.

Shards are Aurora PostgreSQL DB instances that each store a subset of the data for your database, allowing for parallel processing to achieve higher write throughput. Transaction routers manage the distributed nature of the database and present a single database image to database clients.
Transaction routers maintain metadata about where data is stored, parse incoming SQL commands and send those commands to shards, aggregate data from shards to return a single result to the client, and manage distributed transactions to maintain consistency across the entire distributed database. All the nodes that make up your Limitless Database architecture are contained in a DB shard group. The DB shard group has a separate endpoint where your access your Limitless Database resources.
Getting started with Aurora Limitless Database
To get started with a preview of Aurora Limitless Database, you can sign up today and will be invited soon. The preview runs in a new Aurora PostgreSQL cluster with version 15 in the AWS US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions.
As part of the creation workflow for an Aurora cluster, choose the Limitless Database compatible version in the Amazon RDS console or the Amazon RDS API. Then you can add a DB shard group and create new Limitless Database tables. You can choose the maximum Aurora capacity units (ACUs).
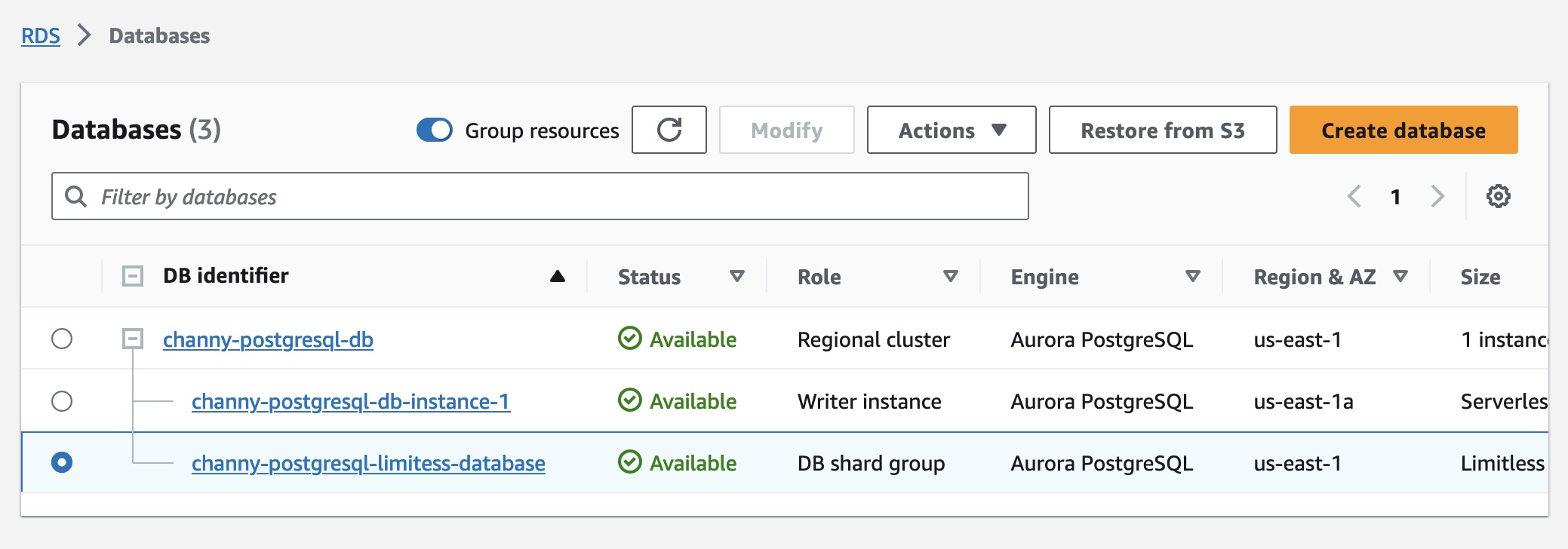
After the DB shard group is created, you can view its details on the Databases page, including its endpoint.
To use Aurora Limitless Database, you should connect to a DB shard group endpoint, also called the limitless endpoint, using psql or any other connection utility that works with PostgreSQL.
There will be two types of tables that contain your data in Aurora Limitless Database:
- Sharded tables – These tables are distributed across multiple shards. Data is split among the shards based on the values of designated columns in the table, called shard keys.
- Reference tables – These tables have all their data present on every shard so that join queries can work faster by eliminating unnecessary data movement. They are commonly used for infrequently modified reference data, such as product catalogs and zip codes.
Once you have created a sharded or reference table, you can load massive data into Aurora Limitless Database and manipulate data in those tables using the standard PostgreSQL queries.
Join the preview
You can join the preview of Amazon Aurora Limitless Database to be among the first to experience all of this power.
Sign up now, give it a try, and please send feedback to AWS re:Post for Amazon Aurora or through your usual AWS support contacts.
— Channy