New – Announcing Automated Data Preparation for Amazon QuickSight Q
In this post that was published in September 2021, Jeff Barr announced general availability of Amazon QuickSight Q. To recap, Amazon QuickSight Q is a natural language query capability that lets business users ask simple questions of their data.
QuickSight Q is powered by machine learning (ML), providing self-service analytics by allowing you to query your data using plain language and therefore eliminating the need to fiddle with dashboards, controls, and calculations. With last year’s announcement of QuickSight Q, you can ask simple questions like “who had the highest sales in EMEA in 2021” and get your answers (with relevant visualizations like graphs, maps, or tables) in seconds.
Data used for analytics is often stored in a data warehouse like Amazon Redshift, and these unfortunately tend to be optimized for programmatic access via SQL rather than for natural language interaction. Furthermore, BI teams, understandably, tend to optimize data sources for consumption by dashboard authors, BI engineers, and other data teams, therefore using technical naming conventions that are optimized for dashboards (for example, “CUST_ID” instead of “Customer”) and SQL queries. These technical naming conventions are not intuitive to be used by business users.
To solve this, BI teams spend hours manually translating technical names into commonly used business language names to prepare the data for natural language questions.
Today, I’m excited to announce automated data preparation for Amazon QuickSight Q. Automated data preparation utilizes machine learning to infer semantic information about data and adds it to datasets as metadata about the columns (fields), making it faster for you to prepare data in order to support natural language questions.
A Quick Overview of Topics in QuickSight Q
Topics became available with the introduction of QuickSight Q. Topics are a collection of one or more datasets that represent a subject area that your business users can ask questions about. Looking at the example mentioned earlier (“who had the highest sales in EMEA in 2021”), one or more datasets (for example, a Sales/Regional Sales dataset) would be selected during the creation of this Topic.
As the author, once the Topic is created:
- You would spend time selecting the most relevant columns from the dataset to add to the Topic (for example, excluding time_stamp, date_stamp columns, etc.). This can be challenging because without visibility to usage data of columns in dashboards and reports, you can find it hard to objectively decide which columns are most relevant to your business users to include in a Topic.
- You would then spend hours reviewing the data and manually curating it to set configurations that are specific to natural language (for example, add “Area” as a synonym for the “Region” column).
- Lastly, you would spend time formatting the data in order to ensure that it is more useful when presented.
-

QuickSight Q Topic
How Does Automated Data Preparation for Amazon QuickSight Q Work?
Creating from Analysis: The new automated data preparation for Amazon QuickSight Q saves time by enabling the capability to create a Topic from analysis and therefore saving you the hours that you would spend doing all the translation by automatically choosing user-friendly names and synonyms based on ML-trained models that seek to find synonyms and common terms for the data field in question. Moreover, instead of you selecting the most relevant columns, automated data preparation for Amazon QuickSight Q automatically selects high-value columns based on how they are used in the analysis. It then binds the Topic to this existing analysis’ dataset and prepares an index of unique string values within the data to enable natural language search.
Automated Field Selection and Classification: I mentioned earlier that automated data preparation for Amazon QuickSight Q selects high value columns, but how does it know which columns are high-value? Automated data preparation for Amazon QuickSight Q automates column selection based on signals from existing QuickSight assets, such as reports or dashboards, to help you create a Topic that is relevant to your business users. In addition to selecting high-value fields from a dataset, automated data preparation for Amazon QuickSight Q also imports new calculated fields that the author has created in the analysis, thereby not requiring them to recreate these in a Topic.
Automated Language Settings: At the beginning of this article, I talked about technical naming conventions that are not intuitive for business users. Now, instead of you spending time translating these technical names, column names are automatically updated with friendly names and synonyms using common terms. Looking at our Sales dataset example, CUST_ID has been assigned a friendly name, “Customer”, and a number of synonyms. Synonyms will now be added automatically to columns (with the option to customize further) to support a wide vocabulary that may be relevant to your business users.

Friendly Names & Synonyms for Columns
Automated Metadata Settings: Automated data preparation for Amazon QuickSight Q detects Semantic Type of a column based on the column values and updates the corresponding configuration automatically. Formats for values will now be set to be used if a particular column is presented in the answer. These formats are derived from formats that you may have defined in an analysis.
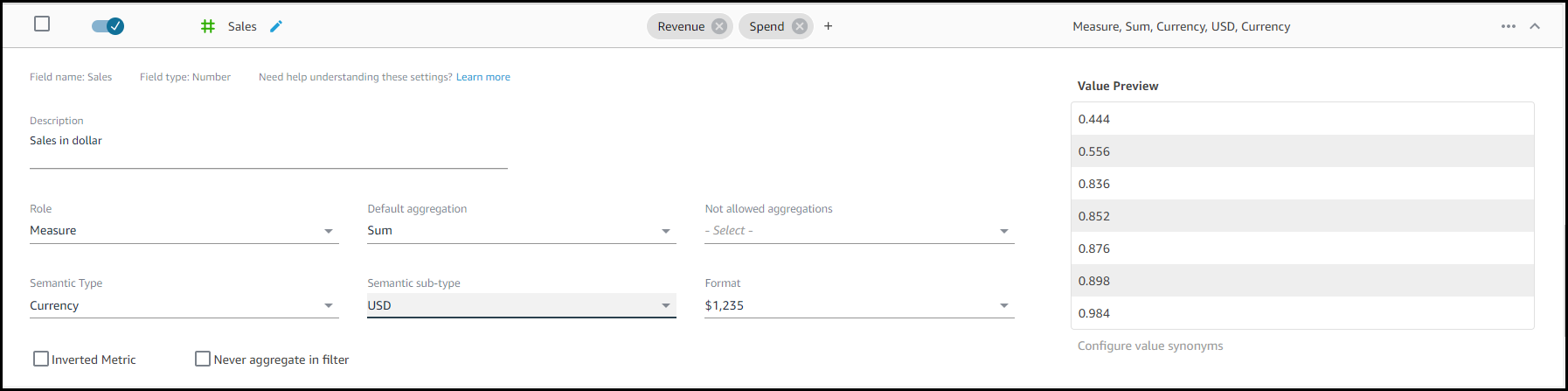
Semantic Type Settings
Available Today
Automated Data Preparation for Amazon QuickSight Q is available today in all AWS Regions where QuickSight Q is available. To learn more, visit the Amazon QuickSight Q page. Join the QuickSight Community to ask, answer, and learn with others in the QuickSight Community.
– Veliswa x